Case Study · Privacy-First AI
Parallel Mind
A privacy-first AI personal reviewer that ingests your emails, chats, and notes, and synthesises them into decisions, risks, and preparation — without your data ever leaving your machine unless you explicitly allow it.
01
The Problem
Drowning in inbound, paying with privacy
Knowledge workers drown in inbound communication. Commitments slip, weak signals — a colleague’s changing tone, a vendor’s stalling tactics — go unnoticed, and preparation for hard conversations happens at the last minute, if at all.
Existing AI assistants solve this by shipping your private correspondence to a cloud provider. Parallel Mind was designed around refusing that trade-off — which made it primarily an architecture problem, not a prompting problem.
02
The Thought Process
Five decisions that shaped the system
Each design question was answered before any code was written. The guiding philosophy: boring, auditable infrastructure; paranoid data handling; honest AI output.
01
Who owns the data?
Local-first, with cloud as a gated escalation — not the default.
Every existing AI assistant solves communication overload by shipping private correspondence to a cloud provider. The foundational decision was to refuse that trade-off entirely: all sensitive processing runs locally via Ollama, everything is encrypted at rest, and cloud inference is opt-in, anonymised, and logged. The architecture follows from this one constraint.
02
How do you make local models good enough?
A 5-tier privacy router instead of one model.
No single local model handles classification, summarisation, and reasoning well. The router matches each task to the cheapest capable tier — a 3B model for PII scans and tagging, a 9B for summarisation, a 12B for lens reasoning — and only escalates to cloud when confidence falls below 0.80 and the content is non-sensitive and anonymised. HIGH-sensitivity content never leaves the machine, unconditionally.
03
What does the AI owe the user?
Honest output: confidence scores, model attribution, routing logs.
An assistant reading your private communication must never present an inference as fact. Every indication carries a confidence score (below 0.6 is visually flagged), every AI-generated record names the model that produced it, and every routing decision — model, tier, sensitivity, latency, cost — is logged and surfaced in the UI as a live privacy score.
04
How much infrastructure does this need?
Boring and auditable: one database, no queues, no Redis.
PostgreSQL 16 with pgvector handles relational data and embeddings in one place — no separate vector database. The ingestion pipeline is plain FastAPI BackgroundTasks with transactional retry and SHA-256 idempotency instead of a queue stack. Fewer moving parts means the privacy guarantees stay auditable; for a single-user local system, queue infrastructure is complexity without payoff.
05
How does raw mail become judgment?
Structured analysis primitives: indications, lenses, insights.
Rather than a chat box, the system mines five typed signals (decisions, replies required, reminders, risks, awareness), applies six cognitive frameworks — negotiation, stakeholder, risk, communication, decision, preparation — grounded in your actual history via pgvector similarity search, and detects cross-message behavioural patterns with evidence attached. Structure makes the output actionable and testable; chat makes it vague.
03
The Core Mechanism
The 5-tier privacy router
Every LLM call passes through the router. Sensitivity decides where a task may run; confidence decides whether it escalates.
Tier 1 · Local fast
llama3.2:3b
Classification, PII scan, tagging
Tier 2 · Local mid
gemma2:9b
Summarisation, indication extraction
Tier 3 · Local large
mistral-nemo:12b
Reasoning, lens output, insights
Tier 4 · Cloud mid
gpt-4o-mini / claude-haiku
Anonymised tasks — opt-in only
Tier 5 · Cloud large
gpt-4o / claude-sonnet
Low-confidence fallback — opt-in only
The non-negotiable rule: HIGH-sensitivity content runs on a local model, always. With cloud mode off — the default — the privacy score reads 100 and nothing ever leaves the machine.
04
The Product
What it looks like
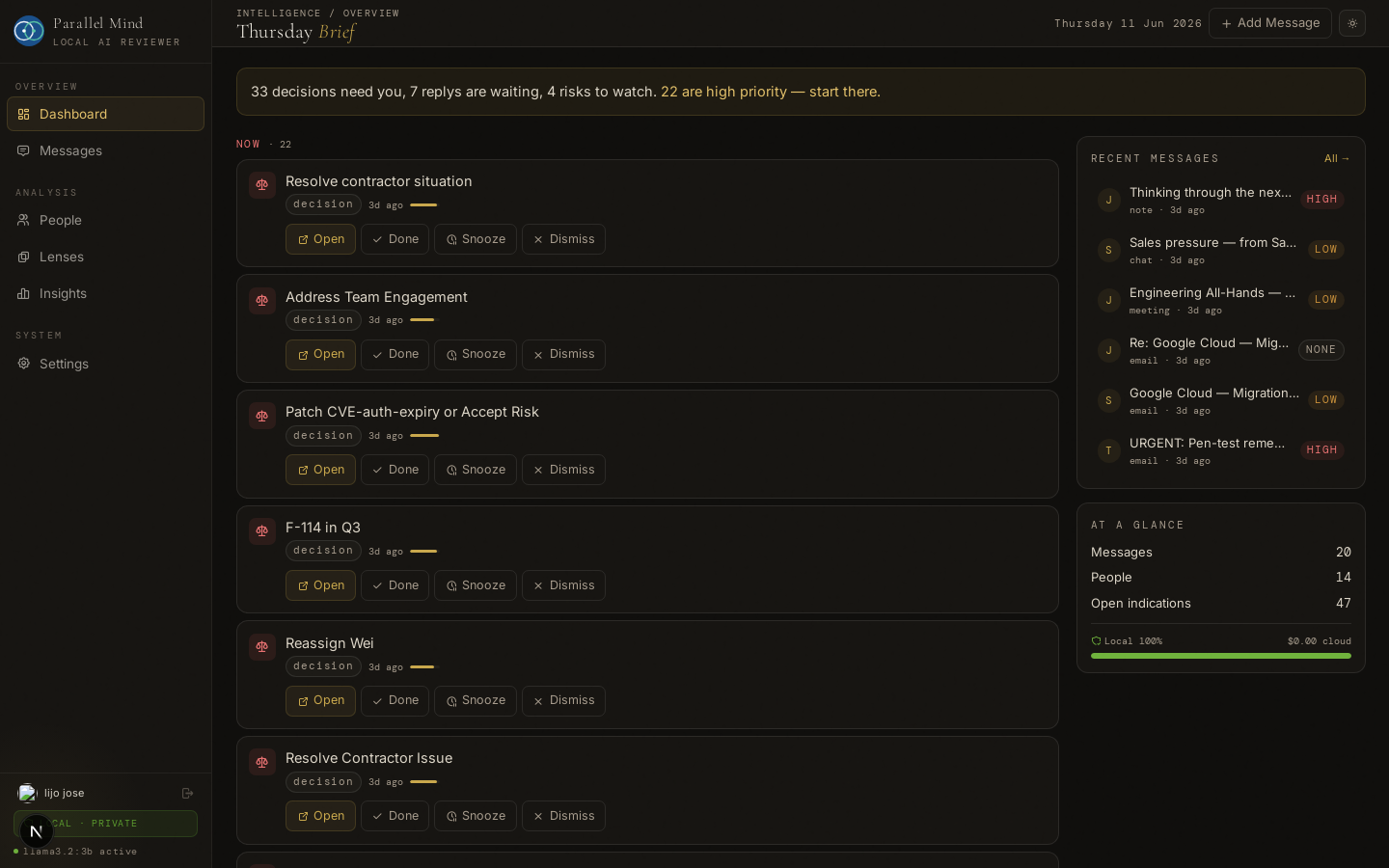
Morning brief — indication queue grouped Now / Today / This week
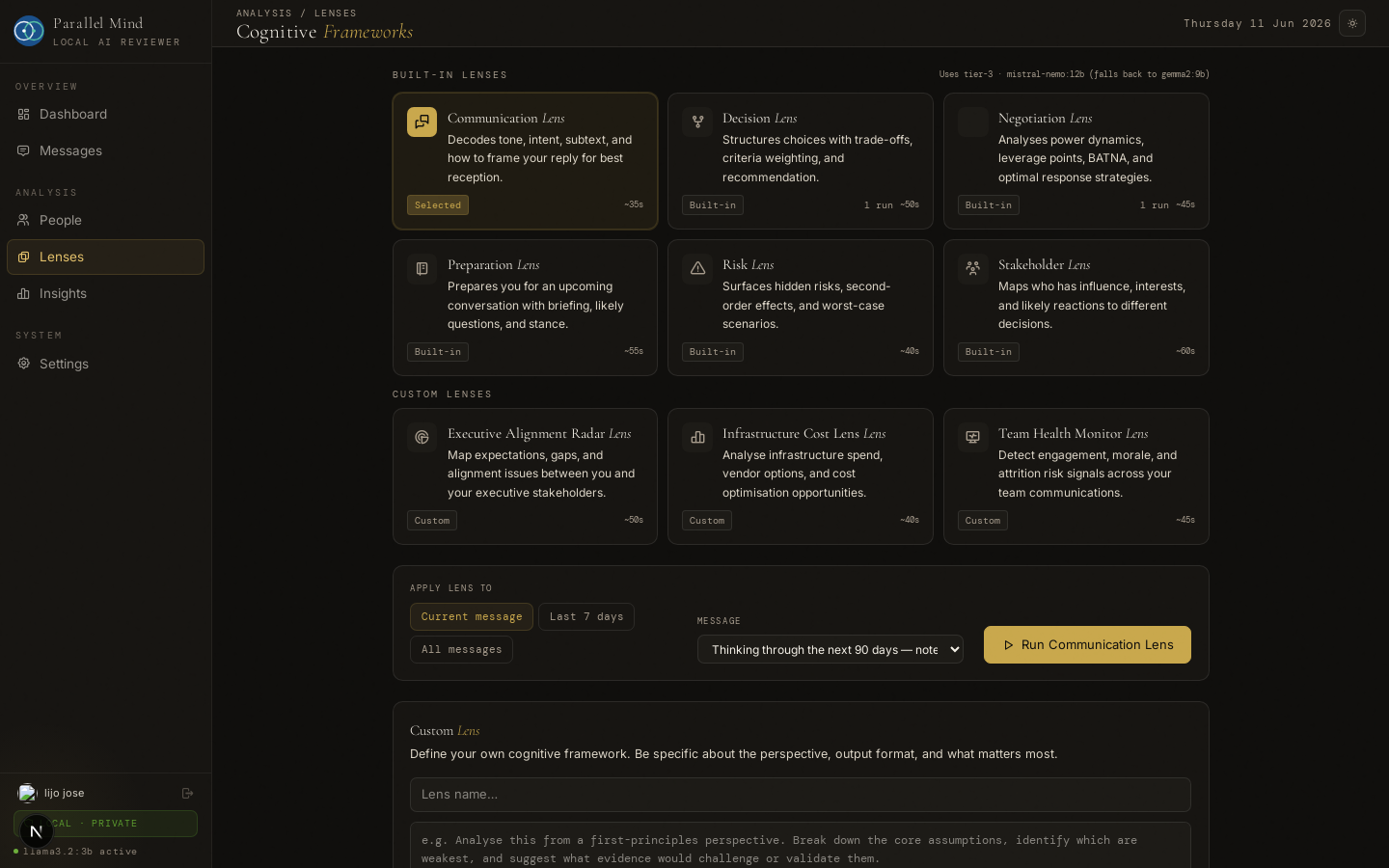
Lens Engine — six cognitive frameworks plus custom lenses
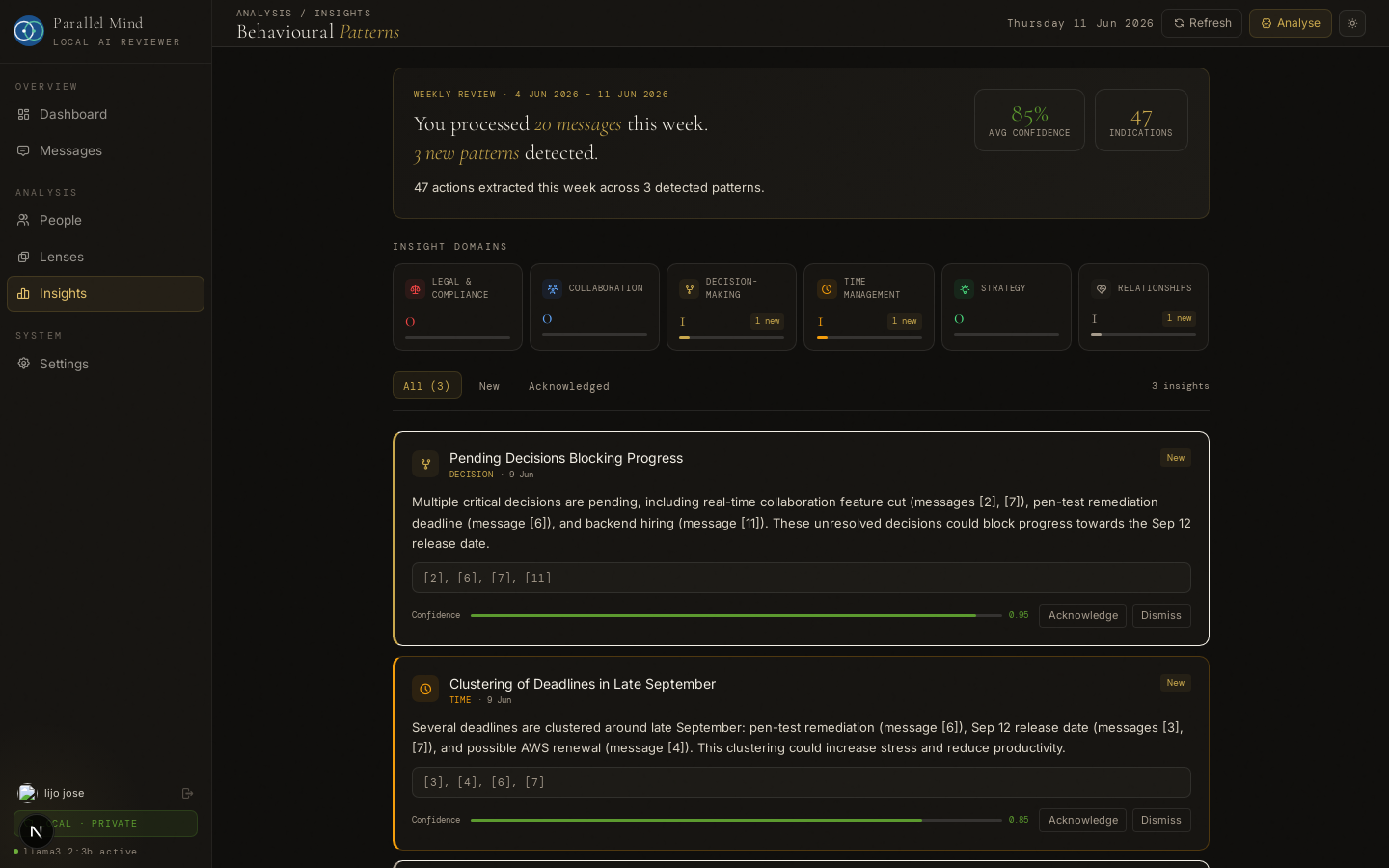
Insight Engine — behavioural patterns with evidence and confidence
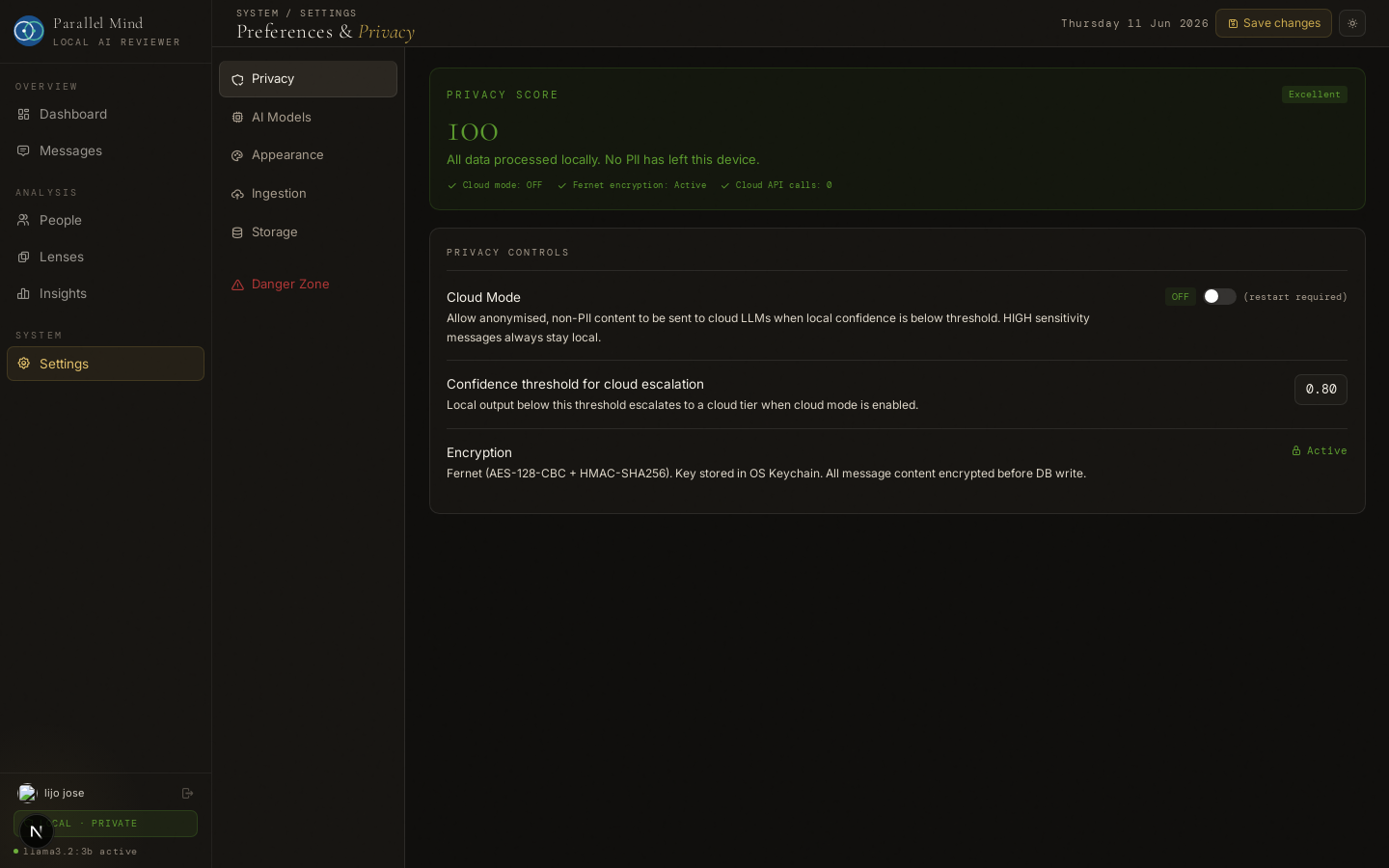
Settings — live privacy score, cloud mode off, encryption active
05
Architecture
At a glance
Frontend
Next.js 14, Tailwind, shadcn/ui, React Query
Backend
FastAPI async, Pydantic v2, SQLAlchemy 2.0
Database
PostgreSQL 16 + pgvector (HNSW)
AI
Ollama local tiers; cloud opt-in, anonymised
Security
Fernet encryption at rest, Firebase auth
Deployment
Docker Compose behind nginx, one port
Designing a privacy-sensitive AI system?
The local-first routing and honest-output patterns here transfer to any domain where the data can’t leave the building.